Here are several examples that may be useful if you
need help debugging your code:
Running perceptron code on a sample data
set, linearlySeparable.arff, for one epoch
results in the following:
(Experiments were run with a learning rate of 0.1 and weights initialized to
0.0.
The called to random_shuffle() in the MLSystemManager code was also commented
out during debugging so the instances would be dealt with in order.)
-------------------------------------------------------------------------------------------------------------
Pattern Bias Target
Weight
Vector Net
Output Change in Weight
-------------------------------------------------------------------------------------------------------------
-0.40 0.30 1.00 1.00
0.00 0.00 0.00 0.00
0.00 -0.04 0.03 0.10
-------------------------------------------------------------------------------------------------------------
-0.30 -0.10 1.00 1.00 -0.04
0.03 0.10 0.11
1.00 0.00 0.00 0.00
-------------------------------------------------------------------------------------------------------------
-0.20 0.40 1.00 1.00 -0.04
0.03 0.10 0.12
1.00 0.00 0.00 0.00
-------------------------------------------------------------------------------------------------------------
-0.10 0.10 1.00 1.00 -0.04
0.03 0.10 0.11
1.00 0.00 0.00 0.00
-------------------------------------------------------------------------------------------------------------
0.10 -0.50 1.00 0.00 -0.04
0.03 0.10 0.08
1.00 -0.01 0.05 -0.10
-------------------------------------------------------------------------------------------------------------
0.20 -0.90 1.00 0.00 -0.05
0.08 0.00 -0.08 0.00
0.00 0.00 0.00
-------------------------------------------------------------------------------------------------------------
0.30 0.20 1.00 0.00
-0.05 0.08 0.00 0.00
1.00 -0.03 -0.02 -0.10
-------------------------------------------------------------------------------------------------------------
0.40 -0.60 1.00 0.00 -0.08
0.06 -0.10 -0.17 0.00
0.00 0.00 0.00
-------------------------------------------------------------------------------------------------------------
Results when the algorithm converges on a final weight vector (~10 epochs):
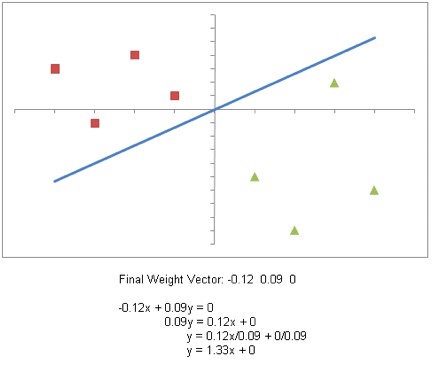
Implementing option (5a) for a perceptron that
handles multiple outputs and running the code on irisSmall.arff
for one epoch results in the following:
(Experiments run with a learning rate of 0.1 and weights initialized to 0.0.)
Dataset name: irisSmall
Number of instances: 9
Learning algorithm: perceptronMultipleOutputs
Evaluation method: training
Calculating accuracy on training set...
-------------------------------------------------------------------------------------------------------------
Pattern &
Bias Target Weight Vector
Net
Output Change in Weight
-------------------------------------------------------------------------------------------------------------
4.9 3.0 1.4 0.2 1.0 1.0 0.00 0.00 0.00
0.00 0.00 0.00 0.0
0.49 0.30 0.14 0.02 0.10
4.9 3.0 1.4 0.2 1.0 0.0 0.00 0.00
0.00 0.00 0.00 0.00
0.0 0.00 0.00 0.00 0.00 0.00
4.9 3.0 1.4 0.2 1.0 0.0 0.00 0.00
0.00 0.00 0.00 0.00
0.0 0.00 0.00 0.00 0.00 0.00
-------------------------------------------------------------------------------------------------------------
6.4 3.2 4.5 1.5 1.0 0.0 0.49 0.30
0.14 0.02 0.10 4.86
1.0 -0.64 -0.32 -0.45 -0.15 -0.10
6.4 3.2 4.5 1.5 1.0 1.0 0.00 0.00
0.00 0.00 0.00 0.00
0.0 0.64 0.32 0.45 0.15 0.10
6.4 3.2 4.5 1.5 1.0 0.0 0.00 0.00
0.00 0.00 0.00 0.00
0.0 0.00 0.00 0.00 0.00 0.00
-------------------------------------------------------------------------------------------------------------
5.8 2.7 5.1 1.9 1.0 0.0 -0.15 -0.02 -0.31 -0.13
0.00 -2.75 0.0 0.00 0.00
0.00 0.00 0.00
5.8 2.7 5.1 1.9 1.0 0.0 0.64 0.32
0.45 0.15 0.10 7.26
1.0 -0.58 -0.27 -0.51 -0.19 -0.10
5.8 2.7 5.1 1.9 1.0 1.0 0.00 0.00
0.00 0.00 0.00 0.00
0.0 0.58 0.27 0.51 0.19 0.10
-------------------------------------------------------------------------------------------------------------
7.0 3.2 4.7 1.4 1.0 0.0 -0.15 -0.02 -0.31 -0.13
0.00 -2.75 0.0 0.00 0.00
0.00 0.00 0.00
7.0 3.2 4.7 1.4 1.0 1.0 0.06 0.05 -0.06
-0.04 0.00 0.24 1.0 0.00
0.00 0.00 0.00 0.00
7.0 3.2 4.7 1.4 1.0 0.0 0.58 0.27
0.51 0.19 0.10 7.69
1.0 -0.70 -0.32 -0.47 -0.14 -0.10
-------------------------------------------------------------------------------------------------------------
4.7 3.2 1.3 0.2 1.0 1.0 -0.15 -0.02 -0.31 -0.13
0.00 -1.20 0.0 0.47 0.32
0.13 0.02 0.10
4.7 3.2 1.3 0.2 1.0 0.0 0.06 0.05 -0.06
-0.04 0.00 0.36 1.0 -0.47
-0.32 -0.13 -0.02 -0.10
4.7 3.2 1.3 0.2 1.0 0.0 -0.12 -0.05 0.04
0.05 0.00 -0.66 0.0 0.00
0.00 0.00 0.00 0.00
-------------------------------------------------------------------------------------------------------------
6.9 3.1 4.9 1.5 1.0 0.0 0.32 0.30 -0.18
-0.11 0.10 2.19 1.0 -0.69
-0.31 -0.49 -0.15 -0.10
6.9 3.1 4.9 1.5 1.0 1.0 -0.41 -0.27 -0.19 -0.06 -0.10
-4.79 0.0 0.69 0.31 0.49
0.15 0.10
6.9 3.1 4.9 1.5 1.0 0.0 -0.12 -0.05 0.04
0.05 0.00 -0.71 0.0 0.00
0.00 0.00 0.00 0.00
-------------------------------------------------------------------------------------------------------------
7.1 3.0 5.9 2.1 1.0 0.0 -0.37 -0.01 -0.67 -0.26
0.00 -7.16 0.0 0.00 0.00
0.00 0.00 0.00
7.1 3.0 5.9 2.1 1.0 0.0 0.28 0.04
0.30 0.09 0.00 4.07
1.0 -0.71 -0.30 -0.59 -0.21 -0.10
7.1 3.0 5.9 2.1 1.0 1.0 -0.12 -0.05 0.04
0.05 0.00 -0.66 0.0 0.71
0.30 0.59 0.21 0.10
-------------------------------------------------------------------------------------------------------------
5.1 3.5 1.4 0.2 1.0 1.0 -0.37 -0.01 -0.67 -0.26
0.00 -2.91 0.0 0.51 0.35
0.14 0.02 0.10
5.1 3.5 1.4 0.2 1.0 0.0 -0.43 -0.26 -0.29 -0.12 -0.10
-3.63 0.0 0.00 0.00 0.00
0.00 0.00
5.1 3.5 1.4 0.2 1.0 0.0 0.59 0.25
0.63 0.26 0.10 4.92
1.0 -0.51 -0.35 -0.14 -0.02 -0.10
-------------------------------------------------------------------------------------------------------------
6.3 3.3 6.0 2.5 1.0 0.0 0.14 0.34 -0.53
-0.24 0.10 -1.68 0.0 0.00
0.00 0.00 0.00 0.00
6.3 3.3 6.0 2.5 1.0 0.0 -0.43 -0.26 -0.29 -0.12 -0.10
-5.71 0.0 0.00 0.00 0.00
0.00 0.00
6.3 3.3 6.0 2.5 1.0 1.0 0.08 -0.10 0.49
0.24 0.00 3.71 1.0
0.00 0.00 0.00 0.00 0.00
-------------------------------------------------------------------------------------------------------------
Running on the full data set iris.arff yields the following results:
Dataset name: iris
Number of instances: 150
Learning algorithm: perceptronMultipleOutputs
Evaluation method: training
Calculating accuracy on training set...
----------------------
Confusion Matrix:
Iris-setosa Iris-versicolor Iris-virginica
Iris-setosa 48.0 2.0
0.0
Iris-versicolor 0.0 49.0 1.0
Iris-virginica 0.0 10.0 40.0
Accuracy by
class:
Iris-setosa: 0.96
Iris-versicolor: 0.98
Iris-virginica: 0.8
Accuracy on all classes: 0.9133333333333333
----------------------
Training set accuracy: 0.9133333333333333
Test set accuracy: 0.9133333333333333
Time to train (in seconds): 0.109
Again, experiments were run with a learning rate of 0.1 and weights initialized
to 0.0. The training set was shuffled after every epoch using a copy of the
random_shuffle method in the MLSystemManager file, and the java random number
generator was seeded with a 0. We
stopped training when the algorithm went for five epochs without a change of
more than 1% in accuracy on the training set. Even with that information, your results probably won't match these exactly; the numbers
here are just intended to provide ballpark figures. (With our code, accuracy
levels ranged from 67% to 95% on the training set depending on the random seed
that was used.)