Network Routing
Overview
In this project you will implement Dyskstra’s algorithm to find paths through a graph representing a network routing problem.Goals
- Understand Dyktra’s algorithm in the context of a real world problem.
- Implement a priority queue with worst-case logarithmic operations.
- Compare two different priority queue data structures for implementing Dykstra’s and empirically verify their differences.
- Understand the importance of proper data structures/implementations to gain the full efficiency potential of algorithms.
Provided Framework
The C# framework is found here. It provides a- A graphical user interface that generates a specified number of points with a given random seed
- A display for the points
- Widgets for each of the functions that need to be implemented
When you hit “Generate” the framework for this project generates a random set of nodes, V, each with 3 randomly selected edges to other nodes. The edges are directed and the edge cost is the Euclidean distance between the nodes. Thus all nodes will have an out-degree of 3, but no predictable value for in-degree. You will be passed an O(|V|) adjacency list representing the graph and including the edge lengths. The nodes are drawn on the image in the provided framework. You can hit “Generate” again to build a new adjacency list (if you change the random seed). The indexes of the nodes are shown for help in debugging, etc.
After generating, clicking on a node (or entering its index in the appropriate box) will highlight the source in green, and clicking another (or, again entering its index in the box) will highlight the destination in red. Each click alternates between the two. After these nodes are selected you can hit “Solve”, and your code should draw the shortest path starting from the source node and following all intermediate nodes until the destination node. Next to each edge between two nodes, display the cost of that segment of the route. Also, in the "Total Path Cost" box, display the total path cost. If the destination cannot be reached from the source then put “unreachable” in the total cost box. Clicking on the screen again will clear the current path while allowing you to set another source/destination pair.
checkboxThe “Solve” button should (potentially) call two different versions of Dykstra’s, one that uses an array to implement the priority queue, and one that uses a heap. (Use the standard Dykstra's algorithm from the text which puts all nodes initially in the queue and finds the shortest path from the source node to all nodes in the network; after running that, then you just need to show the path from the source to the destination.) Both versions should give you the same path cost. While both versions have the same "high-level" big-O complexity for the graphs they generate, they will differ significantly in their runtime (why?). Each time you hit solve and show a path, display the time required for each version, and the times speedup of the heap implementation over the array implementation.
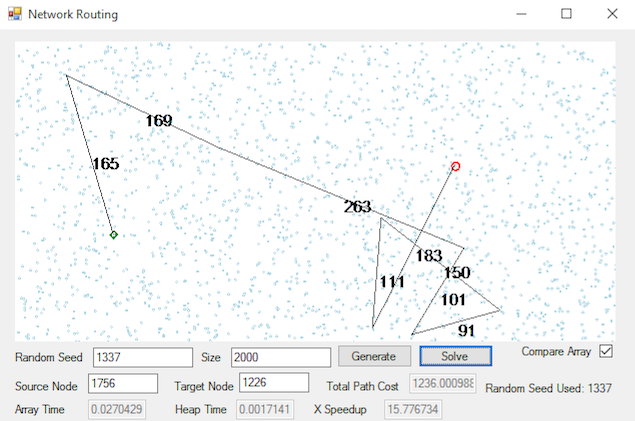
To make sure everything is working correctly, first try some smaller problems that you can solve by hand. Also, at the bottom of this page, we have included a screen shot for a particular 2000 vertex problem, which you can use as a debug check to help ensure your code is working correctly.
Note that here, since each node has a predefined maximum out-degree, O(|E|) = O(|V|).
Note that in a stable network, a node could just run Dykstra’s once for every node in the network and set up a routing table which it could then use for any message. However, for unstable networks (new nodes, outages, etc.) such a table would not necessarily be correct for very long.
To Do
- Implement Dykstra’s algorithm to find shortest paths in a graph.
- Implement two versions of a priority queue class, one using an array as the data structure and one using a heap. For the array implementation, insert and decrease-key are simple O(1) operations, but delete-min will unavoidably be O(|V|). For the heap implementation, all three operations (insert, delete-min, and decrease-key) should be worst case O(|log|V|). If you do a binary heap implementation, you may implement the binary heap with an array, but also remember that decrease-key will be O(|V|) unless you have a separate pointer array into your binary heap, so that you can have fast access to an arbitrary node. Also, don't forget that you will need to adjust the pointers in the pointer array every time you swap elements in the heap. (All this was discussed in detail in class.)
- Write a function (using the “Solve” button) that will find the least cost path from the source to the destination node using both implementations. Draw the shortest path starting from the source node and following all intermediate nodes to the destination node. The functions for drawing should be familiar from the convex hull project. Display the time required for each version, and the time speedup for the heap implementation. Label each edge cost and show the total path cost.
Report
Submit a typed report in PDF format with the following information.- [20] Correctly implement Dysktra’s algorithm and the functionality discussed above. Include a copy of your (well-documented) code in your submission to the TA.
- [20] Correctly implement both versions of a priority queue, one using an array with worst case O(1), O(1) and O(|V|) operations and one using a heap with worst case O(log|V|) operations. For each operation (insert, delete-min, and decrease-key) convince us (refer to your included code) that the complexity is what is required here.
- [10 points] Explain the time and space complexity of both implementations of the algorithm by showing and summing up the complexity of each subsection of your code.
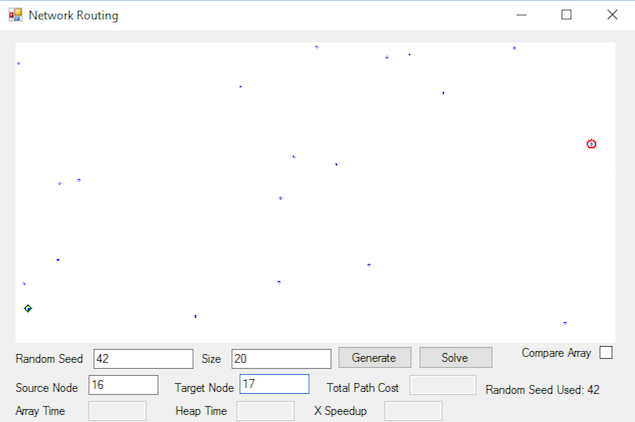
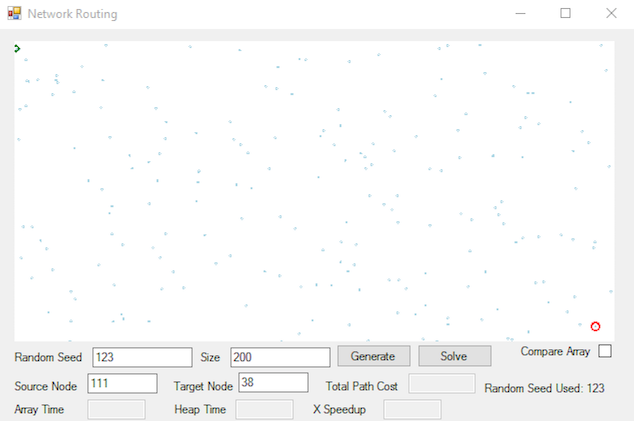
- [20] For Random seed 42 - Size 20 and Random Seed 123 - Size 200, submit a screenshot showing the shortest path
(if one exists) for each of the two source-destination pairs, as shown in the images below.
- For Random seed 42 - Size 20, use the lower left-most node (node 16) as the source and the right-most node (node 17) as the destination, as in the first image.
- For Random seed 123 - Size 200, use the upper left-most node (node 111) as the source and the lower right-most node (node 38) as the destination, as in the second image.
- [20] For different numbers of nodes (100, 1000, 10000, 100000, 1000000), compare the empirical time complexity for Array vs. Heap, and give your best estimate of the difference (for 1000000 nodes, run only the heap version and then estimate how long you might expect your array version to run based on your other results). For each number of nodes do at least 5 tests with different random seeds, and average the results. Redo any case where the destination is unreachable. Each time, start with nodes approximately in opposite corners of the network. Graph your results and also give a table of your raw data (data for each of the runs); in both graph and table, include your one estimated runtime (array implementation for 1000000 points). Discuss the results and give your best explanations of why they turned out as they did.